
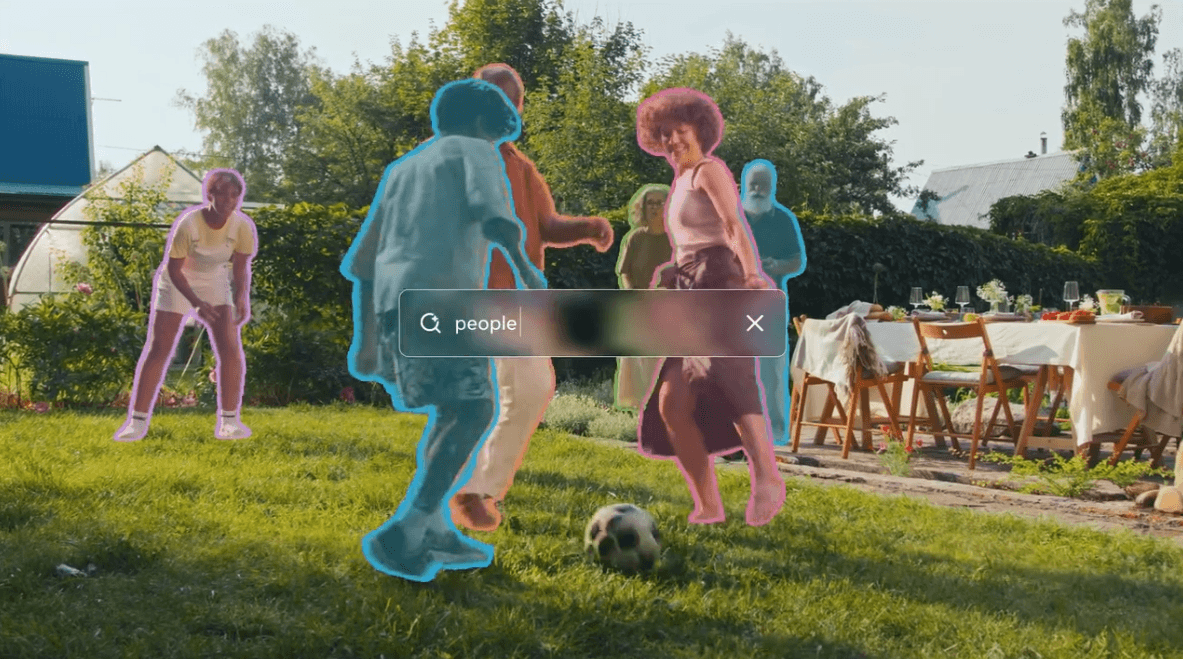
Meta veröffentlicht die dritte Generation seines „Segment Anything Model“. SAM 3 soll Bilder und Videos gleichermaßen verstehen und setzt auf eine neue Trainingsmethode, die menschliche und künstliche Annotatoren kombiniert.
Der Artikel Metas neues KI-Modell SAM 3 verbindet Sprache und Vision flexibler als zuvor erschien zuerst auf The Decoder.
