Nano Banana
Kurzfassung
▾
Quellen
▾
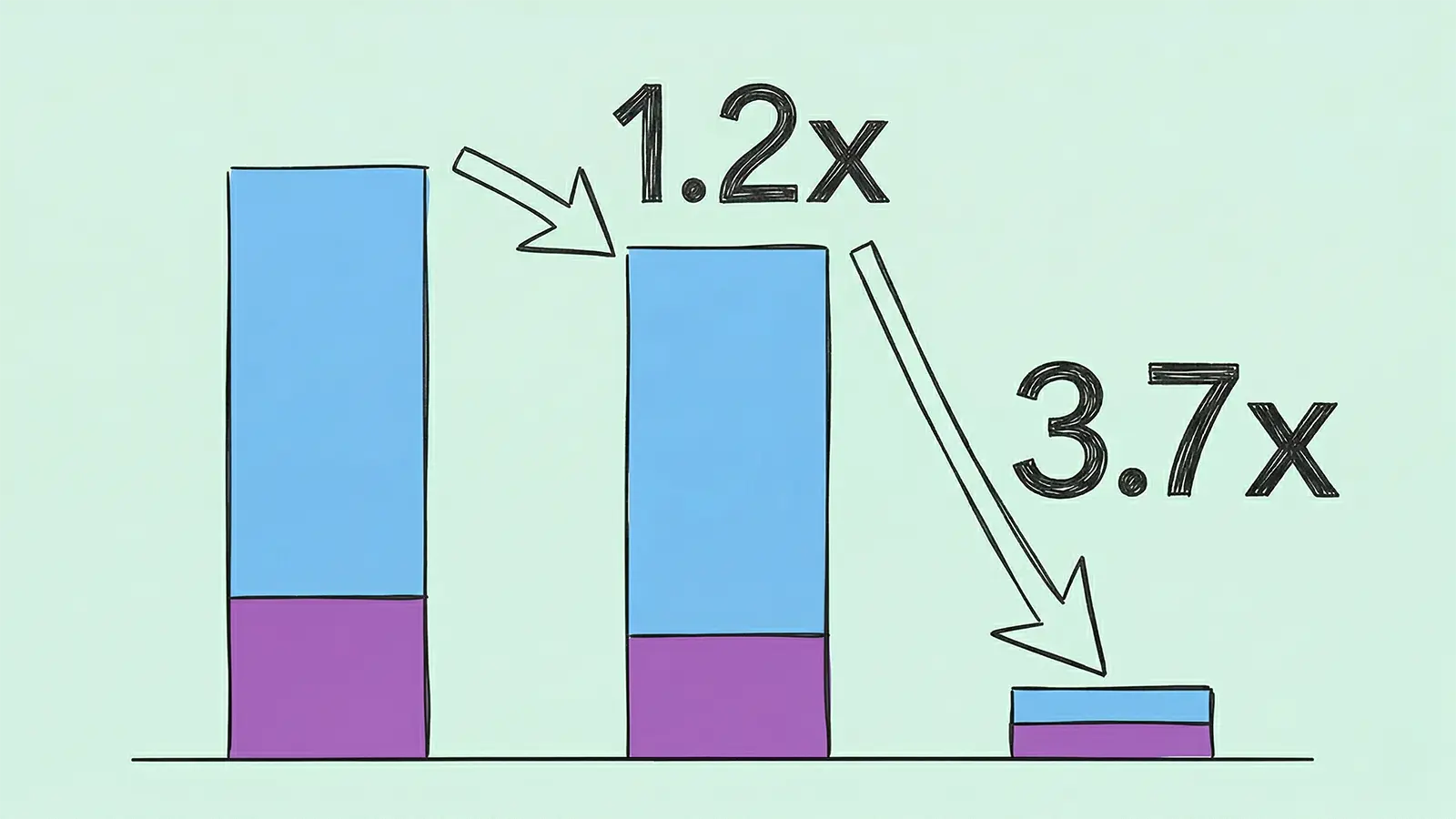
Die siebte TPU-Generation namens Ironwood verbessert die Compute Carbon Intensity im Vergleich zum Vorgänger um den Faktor 3,7.
Dieser Effizienzsprung gelingt primär durch eine verfünffachte Rechenleistung bei der Ausführung von KI-Modellen.
Auch ältere Architekturen wie Trillium und TPU v5e arbeiten dank klugem Server-Scheduling mittlerweile deutlich sparsamer.
Zusätzliche Software-Techniken wie Mixture of Experts und das 8-Bit-Zahlenformat (FP8) reduzieren den Energiebedarf pro Rechenschritt spürbar.
Google Cloud Blog – AI infrastructure efficiency: Ironwood TPUs deliver 3.7x carbon efficiency gains
Die siebte Generation der Tensor Processing Units unter dem Codenamen Ironwood verbessert die »Compute Carbon Intensity« gegenüber dem Vorgänger um den Faktor 3,7. Der Chip fängt den steigenden Energiebedarf von KI-Modellen durch eine verfünffachte Rechenleistung auf. Leistung steigt schneller als Emissionen Die Grundlage für diese Metrik bildet die Compute Carbon Intensity (CCI). Der Wert gibt in Gramm CO2-Äquivalent pro ExaFLOP an, wie viel Treibhausgas für eine Fließkommaoperation entsteht. Die Berechnung schließt sowohl den direkten Betrieb im Rechenzentrum als auch die Emissionen für Herstellung und Transport der Hardware ein. Bei der Ironwood-Architektur sinkt dieser Indikator deutlich ab. Während der Vorgänger TPU v5p insgesamt noch 292 gCO2e/EFLOP erzeugte, verursacht Ironwood lediglich 79 gCO2e/EFLOP. Dieser Rückgang resultiert primär aus dem hohen Leistungszuwachs der Chips. Die effektiv genutzten FLOPs steigen im direkten Vergleich um den Faktor 5, wodurch der relative CO2-Fußabdruck pro einzelner Rechenoperation stark einbricht. + Quelle: Google Software optimiert bestehende Hardware Die Effizienzgewinne beschränken sich nicht ausschließlich auf kommende Hardware-Generationen. Auch bereits installierte Systeme arbeiten mittlerweile messbar sparsamer. Bei der sechsten Generation Trillium fiel die CCI laut den aktuellen Messreihen innerhalb von 15 Monaten um 20 Prozent auf exakt 125 gCO2e/EFLOP. Die Architektur TPU v5e verzeichnet im selben Zeitraum sogar einen Rückgang von 43 Prozent. Eine intelligente Orchestrierung der Serverflotte verteilt die Auslastung präziser und senkt den Stromverbrauch der Maschinen im Leerlauf. Parallel dazu reduzieren moderne Software-Ansätze den reinen Rechenaufwand. Sparse-Architekturen wie Mixture of Experts (MoE) aktivieren punktgenau nur die benötigten Parameter eines KI-Modells. Die verstärkte Nutzung des 8-Bit-Zahlenformats (FP8) halbiert zudem die Anforderungen an die Speicherbandbreite und verdoppelt den Datendurchsatz bei konstant hoher Ausgabequalität. Der Energiebedarf für KI-Workloads sinkt dadurch spürbar durch das Zusammenspiel aus Hardware-Dichte und optimiertem Code. + Quelle: Google Anzeige

