Google
Kurzfassung
▾
Quellen
▾
Google Veo 3.1 führt die Funktion „Ingredients to Video“ ein, womit Charaktere und visuelle Stile durch Referenzbilder exakt beibehalten werden. Das Update optimiert die Erstellung vertikaler Videos aus Porträtfotos speziell für Social-Media-Plattformen wie TikTok oder Reels. Creator erhalten präzisere Kontrolle über technische Parameter wie Kamerafahrten und Beleuchtung für professionellere Ergebnisse.
Google Blog – Veo 3.1 Ingredients to Video: More consistency, creativity and control
The Verge – Google’s Veo now turns portrait images into vertical AI videos
TechCrunch – Google’s update for Veo 3.1 lets users create vertical videos through reference images
Techeblog – Google’s New Veo 3.1 Update Includes Ingredients to Video
Blockchain.news – Google DeepMind Unveils Veo 3.1 Update
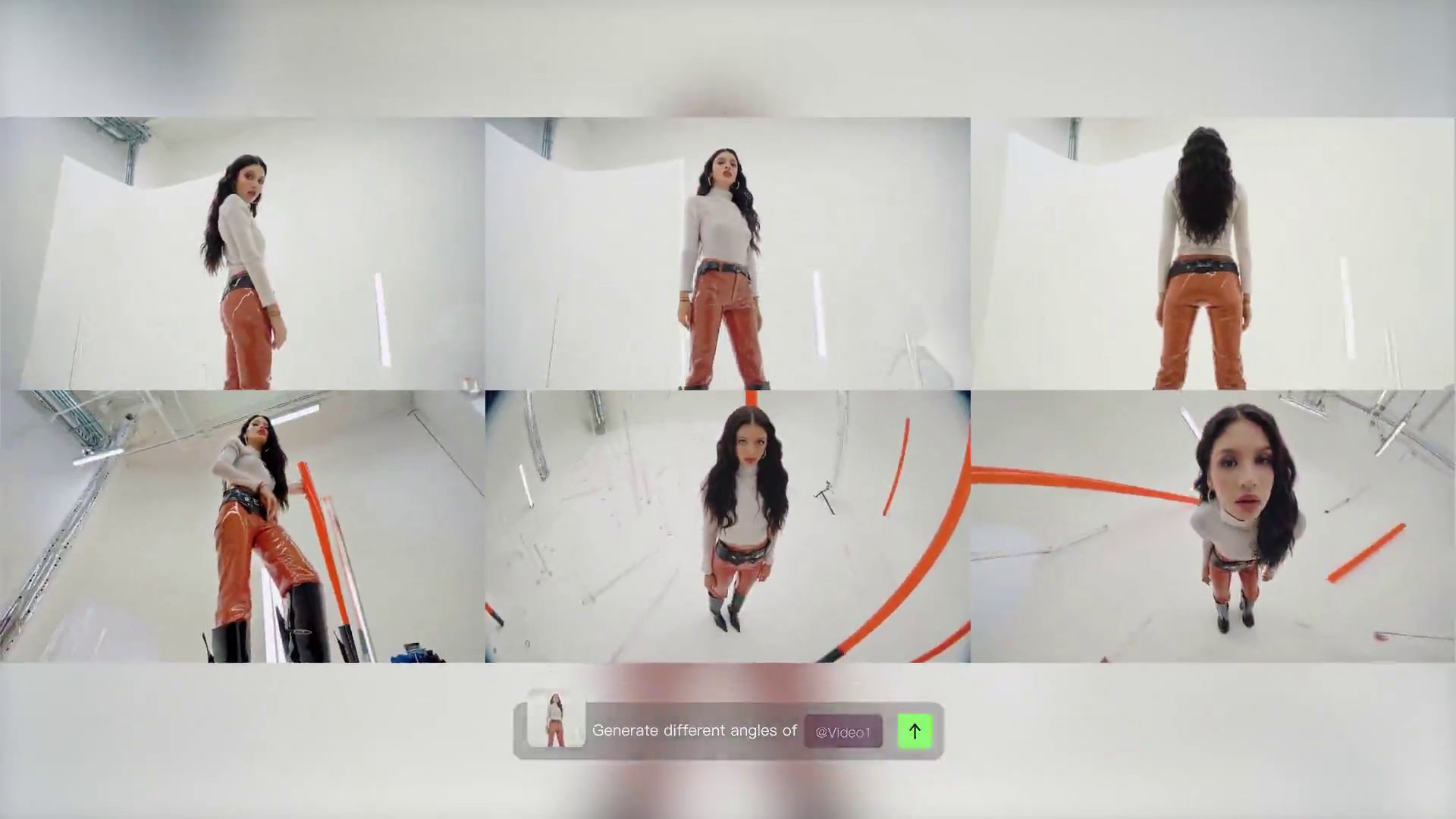
Google veröffentlicht mit Veo 3.1 ein Update, das die bisher größte Schwäche generativer Video-KI adressiert: mangelnde Konsistenz. Durch die Nutzung spezifischer Bild-Referenzen erhalten Creator präzise Werkzeuge an die Hand, um Charaktere und Stile exakt beizubehalten, was professionelle Workflows massiv erleichtert. Das Ende des Zufallsprinzips Bisher glich die Erstellung von KI-Videos oft einem Glücksspiel, bei dem Textprompts zu variierenden Ergebnissen führten. Mit der neuen Funktion „Ingredients to Video“ ändert DeepMind diesen Ansatz grundlegend. Nutzer laden nun Referenzbilder hoch, die als visuelle Ankerpunkte dienen. Diese „Zutaten“ fungieren als strikte Vorgabe für das Modell. Ein hochgeladenes Bild einer Person sorgt dafür, dass deren Gesichtszüge und Kleidung im generierten Video erhalten bleiben. Ebenso lässt sich ein stilistisches Referenzbild nutzen, um den visuellen Look – etwa Cyberpunk oder Aquarell – über mehrere Szenen hinweg zu fixieren. Die KI verknüpft diese visuellen Inputs mit den textlichen Regieanweisungen. Das System versteht den Kontext der Bilder und animiert diese entsprechend der Prompt-Vorgaben, ohne die ursprüngliche Identität oder Ästhetik zu verzerren. Dies ermöglicht erstmals echtes Storytelling mit wiederkehrenden Charakteren ohne aufwendiges Post-Processing.
Vertikaler Content im Fokus Neben der Konsistenz legt Google einen klaren Schwerpunkt auf Social-Media-Formate. Veo 3.1 unterstützt nun nativ die Erstellung vertikaler Videos aus Porträt-Bildern. Content Creator müssen Referenzbilder im Hochformat nicht mehr mühsam zuschneiden oder qualitativ minderwertig skalieren. Die KI generiert den Bewegtbildinhalt direkt im passenden Seitenverhältnis für Plattformen wie TikTok oder Instagram Reels. Das Modell füllt fehlende Bildinformationen am oberen und unteren Rand intelligent auf, falls das Ausgangsmaterial nicht ganz passt. Dieser Schritt zeigt Googles Ambition, Veo nicht nur als experimentelles Tool, sondern als Produktionsmittel für den täglichen Social-Media-Einsatz zu etablieren. Die Hürde zwischen einem statischen Foto und einem viralen Short-Video wird damit fast vollständig entfernt.
Präzision für professionelle Workflows Das Update bringt zudem eine verfeinerte Steuerung technischer Parameter mit sich. Regieanweisungen bezüglich Kamerabewegungen und Beleuchtung werden von Veo 3.1 deutlich akkurater umgesetzt als in der Vorgängerversion. Filmemacher können spezifizieren, ob eine Szene im harten Gegenlicht oder mit weicher Ausleuchtung stattfinden soll. Auch komplexe Kamerafahrten, wie ein Dolly-Zoom oder ein langsamer Panoramaschwenk, lassen sich gezielter abrufen. Das System interpretiert technische Begriffe nun eher wie eine Render-Engine und weniger wie ein Sprachmodell. Die Kombination aus visueller Konsistenz durch „Ingredients“ und technischer Kontrolle macht Veo 3.1 zu einem ernsthaften Konkurrenten für traditionelle Animationssoftware. Es schließt die Lücke zwischen reiner Text-zu-Video-Spielerei und kontrollierbarer Videoproduktion. Anzeige