
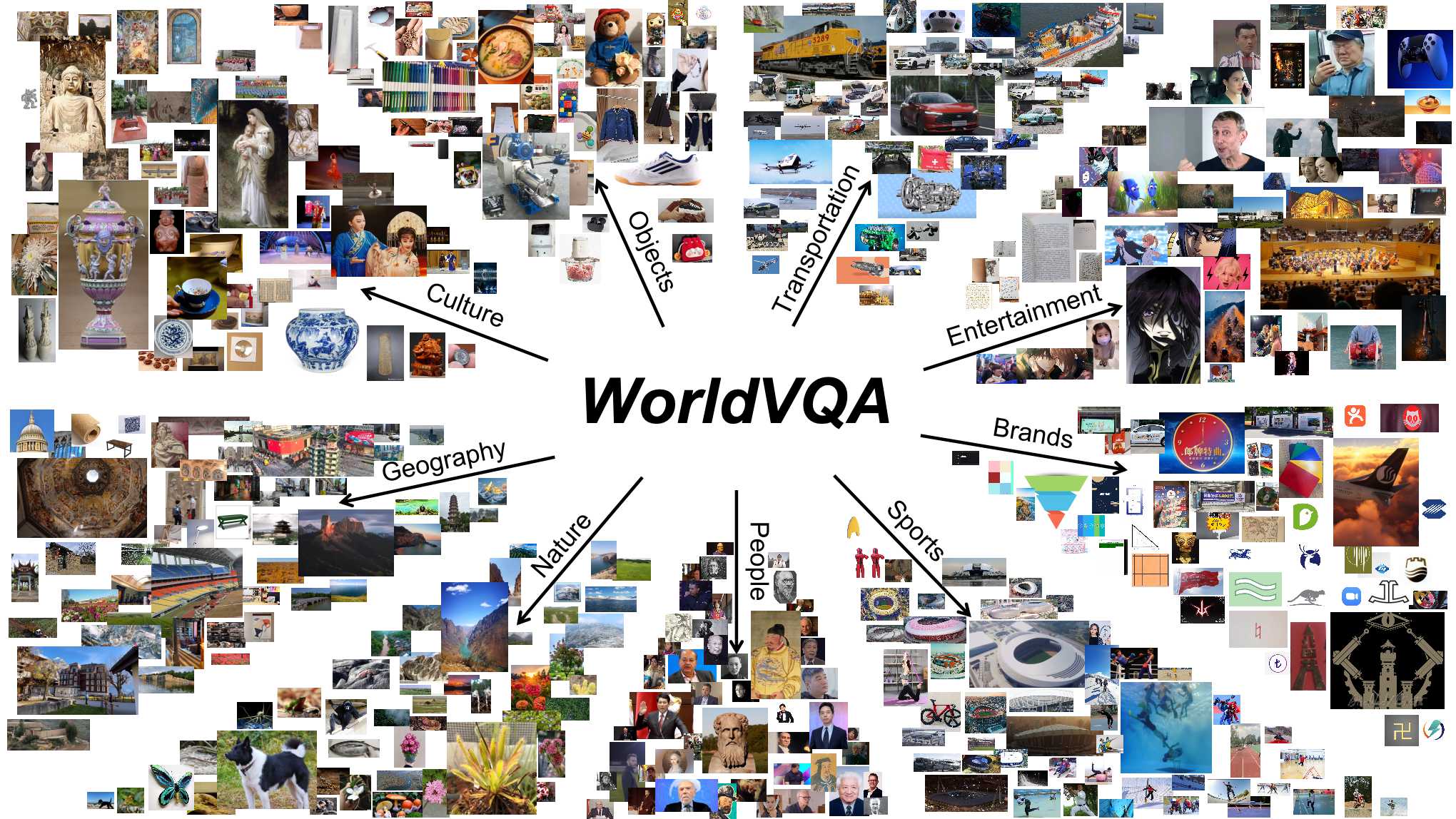
Ein neuer Härtetest für multimodale KI-Modelle offenbart fundamentale Schwächen: Der Benchmark „WorldVQA“ prüft, ob KI-Modelle visuelle Objekte tatsächlich erkennen. Selbst Spitzenreiter wie Gemini 3 Pro scheitern an der 50-Prozent-Marke und neigen zu massiver Selbstüberschätzung, wenn sie mit spezifischen Details statt generischen Begriffen konfrontiert werden.
Der Artikel KI-Modelle erkennen oft nicht, was sie sehen erschien zuerst auf The Decoder.
